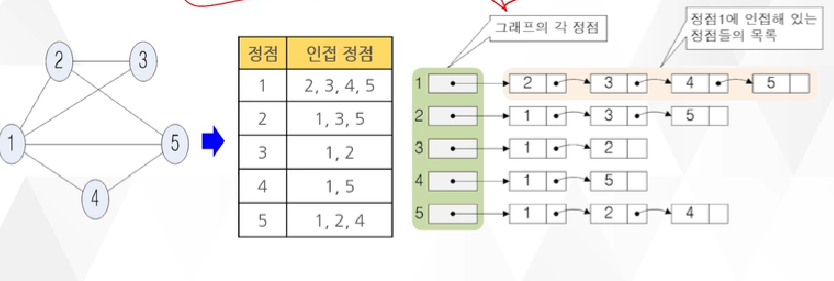
1. 오일러 사이클 (간선 탐색 방법) ① 그래프 이론 : 유한개의 정점과 간선의 결합 방법에 대한 이론 ② 해밀턴 문제 - 12면체 20개의 각 정점에 도시 이름을 적고 어느 한 도시에서 출발하여 모서리를 따라서 다른 모든 19개 도시 방문하고 처음 출발한 도시로 돌아오는 게임 - 각 도시는 단 한 번만 방문 가능 ③오일러 사이클 - 2개의 섬과 7개의 다리로 구성된 공원에서 7개의 다리를 모두 지나가는데 이미 지나갔던 다리는 다시 거치지 않고 갈 수 있는 전체 경로를 해결하는데 오일러는 그래프 이론 사용. - 오일러는 이 문제를 해결하는데 각 정점에 연결된 간선의 개수가 모두 짝수일때만 가능함을 증명 - 각 간선을 정확하게 한번씩만 경유해서 그래프의 모든 간선을 지날 수 있는 경로가 존재하고, 출발 ..